
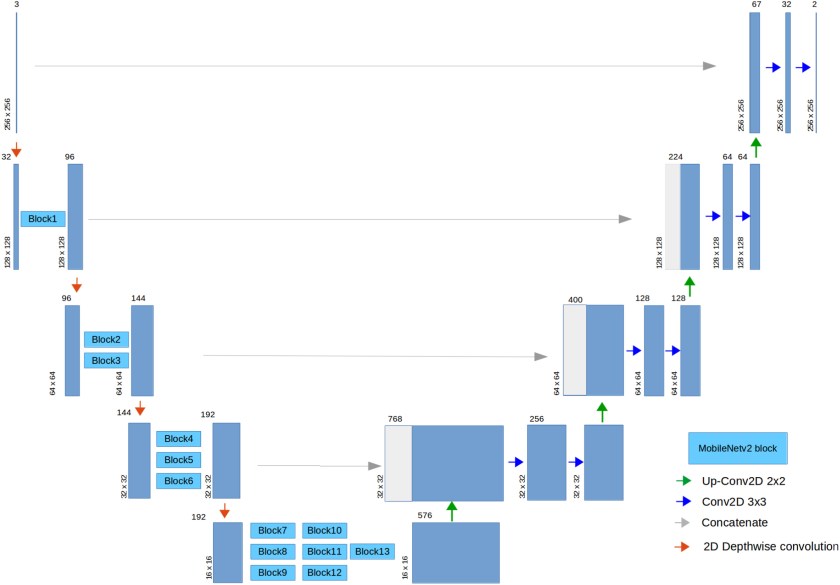
with mobilenetv2 in the encoder
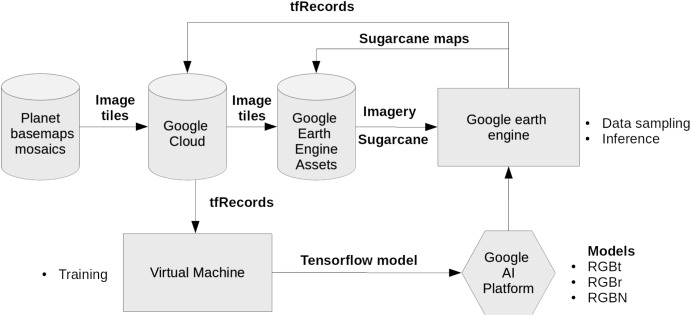
lightweight networks can be very useful to reduce computational costs and speed up training and inference. The script below can be used to train a model after the records are exported from Google Earth engine.
Find more info in this paper

Use the code below and change the paths to the ones on your desktop / server
import os
import sys
import tensorflow as tf
import glob
from functools import partial
from tensorflow.python import keras
from tensorflow.python.keras import layers, losses, models, optimizers, Model, metrics
from tensorflow.python.keras import backend as K
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
from tensorflow.keras.metrics import Recall, Precision
from tensorflow.keras.layers import UpSampling2D, Input, Concatenate, Conv2D, Activation, BatchNormalization
from tensorflow.keras import callbacks
from tensorflow.keras.layers import Input, Conv2D, SeparableConv2D, \
Add, Dense, BatchNormalization, ReLU, MaxPool2D, GlobalAvgPool2D, Conv2D
from tensorflow.keras.applications import MobileNetV2
# Read a serialized example into the structure defined by FEATURES_DICT
def parse_tfrecord(example_proto, features=None, labels=None, patch_shape=None):
keys = features + labels
columns = [
tf.io.FixedLenFeature(shape=patch_shape, dtype=tf.float32) for k in keys
]
proto_struct = dict(zip(keys, columns))
inputs = tf.io.parse_single_example(example_proto, proto_struct)
inputs_list = [inputs.get(key) for key in keys]
stacked = tf.stack(inputs_list, axis=0)
stacked = tf.transpose(stacked, [1, 2, 0])
return tf.data.Dataset.from_tensors(stacked)
# Function to read, parse and format to tuple a set of input tfrecord file
def to_tuple(dataset, n_features=None):
features = dataset[:, :, :, :n_features]
labels = dataset[:, :, :, n_features:]
return features, labels
# read the tensorflow records
def get_dataset(files, features, labels, patch_shape, batch_size,
buffer_size=1000, training=False, **kwargs):
parser = partial(parse_tfrecord,
features=features,
labels=labels,
patch_shape=patch_shape
)
split_data = partial(to_tuple, n_features=len(features))
dataset = tf.data.TFRecordDataset(files, compression_type='GZIP')
dataset = dataset.interleave(parser, num_parallel_calls=tf.data.experimental.AUTOTUNE)
# for training we apply random transform for data augmentation
if training:
dataset = dataset.shuffle(buffer_size, reshuffle_each_iteration=True).batch(batch_size) \
.map(random_transform, num_parallel_calls=tf.data.experimental.AUTOTUNE) \
.map(split_data, num_parallel_calls=tf.data.experimental.AUTOTUNE)
else:
dataset = dataset.batch(batch_size).map(split_data, num_parallel_calls=tf.data.experimental.AUTOTUNE)
return dataset
# calculate recall
def recall_m(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
# calculate precision
def precision_m(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
# calculate f1 score
def f1_m(y_true, y_pred):
precision = precision_m(y_true, y_pred)
recall = recall_m(y_true, y_pred)
return 2 * ((precision * recall) / (precision + recall + K.epsilon()))
# calculate dice coefficient
def dice_coef(y_true, y_pred, smooth=1):
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f)
return (2. * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
# calculate the dice loss
def dice_loss(y_true, y_pred, smooth=1):
intersection = K.sum(K.abs(y_true * y_pred), axis=-1)
true_sum = K.sum(K.square(y_true), -1)
pred_sum = K.sum(K.square(y_pred), -1)
return 1 - ((2. * intersection + smooth) / (true_sum + pred_sum + smooth))
# apply random data transform
def random_transform(dataset):
x = tf.random.uniform(())
if x < 0.10:
dataset = tf.image.flip_left_right(dataset)
elif tf.math.logical_and(x >= 0.10, x < 0.20):
dataset = tf.image.flip_up_down(dataset)
elif tf.math.logical_and(x >= 0.20, x < 0.30):
dataset = tf.image.flip_left_right(tf.image.flip_up_down(dataset))
elif tf.math.logical_and(x >= 0.30, x < 0.40):
dataset = tf.image.rot90(dataset, k=1)
elif tf.math.logical_and(x >= 0.40, x < 0.50):
dataset = tf.image.rot90(dataset, k=2)
elif tf.math.logical_and(x >= 0.50, x < 0.60):
dataset = tf.image.rot90(dataset, k=3)
elif tf.math.logical_and(x >= 0.60, x < 0.70):
dataset = tf.image.flip_left_right(tf.image.rot90(dataset, k=2))
else:
pass
return dataset
# flip data up and down
def flip_inputs_up_down(inputs):
return tf.image.flip_up_down(inputs)
# flip data left and right
def flip_inputs_left_right(inputs):
return tf.image.flip_left_right(inputs)
# transpose data
def transpose_inputs(inputs):
flip_up_down = tf.image.flip_up_down(inputs)
transpose = tf.image.flip_left_right(flip_up_down)
return transpose
# rotate the data 90 degrees
def rotate_inputs_90(inputs):
return tf.image.rot90(inputs, k=1)
# rotate 180 degrees
def rotate_inputs_180(inputs):
return tf.image.rot90(inputs, k=2)
# rotate 270 degrees
def rotate_inputs_270(inputs):
return tf.image.rot90(inputs, k=3)
# function to build the unet with mobilenetv2 in the encoder
def build_model_mobilenet():
# change the number of bands from 4 to 3 when using rgb.
inputs = Input(shape=(None, None,4), name="input_image")
# use only rgb when using imagenet
#encoder = MobileNetV2(input_tensor=inputs, weights="imagenet", include_top=False)
encoder = MobileNetV2(input_tensor=inputs, weights=None, include_top=False)
skip_connection_names = ["input_image", "block_1_expand_relu", "block_3_expand_relu", "block_6_expand_relu"]
encoder_output = encoder.get_layer("block_13_expand_relu").output
f = [32, 64, 128, 256]
x = encoder_output
for i in range(1, len(skip_connection_names)+1, 1):
x_skip = encoder.get_layer(skip_connection_names[-i]).output
x = UpSampling2D((2, 2))(x)
x = Concatenate()([x, x_skip])
x = Conv2D(f[-i], (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Conv2D(f[-i], (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Conv2D(2, (2, 2), padding="same")(x)
x = Activation("sigmoid")(x)
model = Model(inputs, x)
return model
# function to get the model
def get_model(input_optimizer, input_loss_function, evaluation_metrics):
model = build_model_mobilenet()
model.summary()
model.compile(
optimizer = input_optimizer,
loss = input_loss_function,
metrics = evaluation_metrics
)
return model
if __name__ == "__main__":
# get the number of gpu;s
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
# get distributed strategy and apply distribute i/o and model build
strategy = tf.distribute.MirroredStrategy()
print('Number of devices: {}'.format(strategy.scope()))
# Set the path to the raw data
# this expects three folders with training, testing and validation data
raw_data_path = r"/path/to/"
# Define the path to the log directory for tensorboard
log_dir = r'/path/to/log'
# Define the directory where the models will be saved
model_dir = r'/path/to/'
# Specify inputs (Landsat bands) to the model and the response variable.
# the names should be similar as the ones you exported from GEE
BANDS = ['red','green','blue',"nir"]
# these arte the response variables that you defined in GEE
RESPONSE = ["crops","other"]
# we combine the bands and response variables
FEATURES = BANDS + RESPONSE
# we define the training size here
TRAIN_SIZE = 120000
BATCH_SIZE = 12
EPOCHS = 40
BUFFER_SIZE = 4000
optimizer = 'ADAM'
eval_metrics = [metrics.categorical_accuracy]
eval_metrics = [metrics.categorical_accuracy, f1_m, precision_m, recall_m]
# Specify the size and shape of patches expected by the model.
# this is the kernel size specified in GEE. recommended to use 256 or 128
kernel_size = 128
kernel_shape = [kernel_size, kernel_size]
COLUMNS = [tf.io.FixedLenFeature(shape=kernel_shape, dtype=tf.float32) for k in FEATURES]
FEATURES_DICT = dict(zip(FEATURES, COLUMNS))
PATCH_SHAPE = (kernel_size, kernel_size)
training_files = glob.glob(raw_data_path + '/training/*')
training_ds = get_dataset(training_files, BANDS, RESPONSE, PATCH_SHAPE, BATCH_SIZE,
buffer_size=BUFFER_SIZE, training=True).repeat()
testing_files = glob.glob(raw_data_path + '/testing/*')
testing_ds = get_dataset(testing_files, BANDS, RESPONSE, PATCH_SHAPE, BATCH_SIZE,
buffer_size=BUFFER_SIZE, training=True).repeat()
validation_files = glob.glob(raw_data_path + '/validation/*')
validation_ds = get_dataset(testing_files, BANDS, RESPONSE, PATCH_SHAPE, BATCH_SIZE,
buffer_size=BUFFER_SIZE, training=False)
# run on multiple gpu if possible
with strategy.scope():
model = get_model(optimizer, dice_loss, eval_metrics)
CALLBACK_PARAMETER = 'val_loss'
# set the early stopping algorithm
early_stopping = callbacks.EarlyStopping(
monitor=CALLBACK_PARAMETER, patience=12, verbose=0,
mode='auto', restore_best_weights=True)
# Fit the model to the data
model.fit(
x = training_ds,
epochs = EPOCHS,
steps_per_epoch =int(TRAIN_SIZE / BATCH_SIZE),
validation_data = testing_ds,
validation_steps = 100,
callbacks = [tf.keras.callbacks.TensorBoard(log_dir),early_stopping]
)
# Save the model
model.save(model_dir, save_format='tf')
# evaluate the performance of the model
model.evaluate(val_ds)
